Witaj, 2018 roku!
Nie planowałem co prawda rozpoczynać sezonu blogowego w połowie sierpnia, ale szczęśliwie mogę tym razem odezwać się z czymś więcej niż zwyczajowym "No hej, nie było mnie rok, teraz chyba będę, wpisy nadchodzą — kiedyś…". Udało mi się nareszcie skończyć punkt pierwszy, sam szczyt moich list todo od niemal roku. Z lekką dumą informuję, że znajdujesz się teraz na nowej, odświeżonej wersji mojej strony.
Prawdopodobnie… nie zauważyłeś różnicy. I nie są to problemy z cache przeglądarki, a zupełnie zamierzony zabieg. Uznałem, że obecna, czteroletnia forma strony jest w dalszym ciągu adekwatna i (szczególnie przy moich marnych umiejętnościach graficznych) nie ma się co silić na rewolucję. Zrobiłem więc ewolucję, która na drugi rzut oka manifestuje się w najróżniejsze sposoby.
Żegnaj, WordPressie!
Po pierwsze, po ponad ośmiu latach i po raz pierwszy od tchnięcia życia w sobak.pl pożegnałem się z WordPressem. Wspaniałe to było osiem lat, nie zapomnę ich nigdy. Poważnie mówiąc, nie było źle. Nie potrafię wskazać jednego momentu przełomowego, przelania się czary goryczy, które spowodowałoby że rozżalony powiedziałbym dość. Co więc zadecydowało? Suma trzech czynników:
-
Dawka zdrowej ambicji. Nie wypada szewcowi chodzić w najtańśzych butach z sieciówki i nie wypada programiście technologii webowych tworzyć swojej wizytówki na pierwszym lepszym darmowym systemie.
-
Obawy odnośnie bezpieczeństwa. Nie zamierzam tu powielać szeroko rozpowszechnionych mitów. Rdzeń WordPressa jest bezpieczny, pomimo kilku istotnych wtop z zakresu procedowania luk bezpieczeństwa, WordPress w swojej bazowej formie skutechnie opiera się większości ataków.
To, co można powiedzieć o samym gołym produkcie, nie do końca jest jednak prawdą w wypadku niezliczonych wtyczek. Tak więc w obliczu migracji na VPS-a (o której słów kika za chwilę) poszukiwałem czegoś, co nie wprowadzi mnie na pole minowe.
-
Potrzeba customizacji. Raz jeszcze przyznać trzeba, że WordPress generalnie rozszerzalny jest. Twierdzenie inaczej byłoby zanegowaniem faktu istnienia tak wielu wtyczek i motywów do niego.
Nie oznacza to jednak, że owe rozszerzanie należy w roku 2018 do przyjemnych. Mimo, że sam jestem autorem kilku z funkcjonalności integrujących się dosyć mocno w poprzednią wersję witryny, to tworzenie tychże można porównać do szambonurkowania. Wraz z rosnącą ilością zmian, które chciałem i chciałbym wreszcie wprowadzić na swojej stronie potrzebowałem czegoś, w czym czułbym się absolutnie swobodnie.
Dlatego też zdecydowałem się na stworzenie własnego backendu w oparciu o framework Laravel, roboczo określonego nazwą kodową Perception (podziękowania dla winka, jak zawsze niezastąpionego w spontanicznym wymyślaniu nazw). Teoretycznie jest to prosta aplikacja CRUD-owa, więc nie będę za wiele rozpisywał się na temat szczegółów implementacyjnych. Chcę jedynie wspomnieć o jednej ważnej decyzji powiązanej ze wspomnianym wyżej poszukiwaniem bezpieczeństwa. Z tego powodu, a także chęci uproszczenia sobie życia — zarówno w momencie developowania jak i korzystania z platformy — zdecydowałem się na zupełny brak panelu administracyjnego.
Obecna implementacja czerpie mocno z konceptu generatorów stron statycznych. Źródłem jej danych są bowiem statyczne pliki tekstowe. W przeciwieństwie jednak do wcześniej wymienionych generatorów nie są z nich tworzone gotowe pliki HTML, a jedynie przejściowa, tymczasowa baza danych, która pozwala na wprowadzenie dowolnej ilości dynamiki i w zasadzie klayczny rozwój aplikacji WWW. Jak wspomniałem jest to też wygodniejsze dla mnie jako użytkownika, bo oznacza że nie muszę walczyć z dowolnym skryptem, próbując do niego dodać wsparcie Markdowna czy używać desktopowego edytora tylko po to, aby później wkleić wynik swojej pracy do formularza na stronie.
Harder, Better, Faster, Stronger
Dużo uwagi poświęciłem poprawie wydajności działania strony. Począwszy od przeniesienia się na szybszy serwer, przez optymalizację backendu, aż po upewnienie się, że wynik jego pracy może zostać szybko pobrany i obsłużony przez przeglądarkę. Zacząłem od podstaw, czyli zmniejszenia ilości i rozmiaru tekstu wysyłanego do klienta, wagi obrazków, zapytań do innych zasobów et ceterra. Wynik całej tej operacji przedstawia skrótowo poniższa galeria.
-
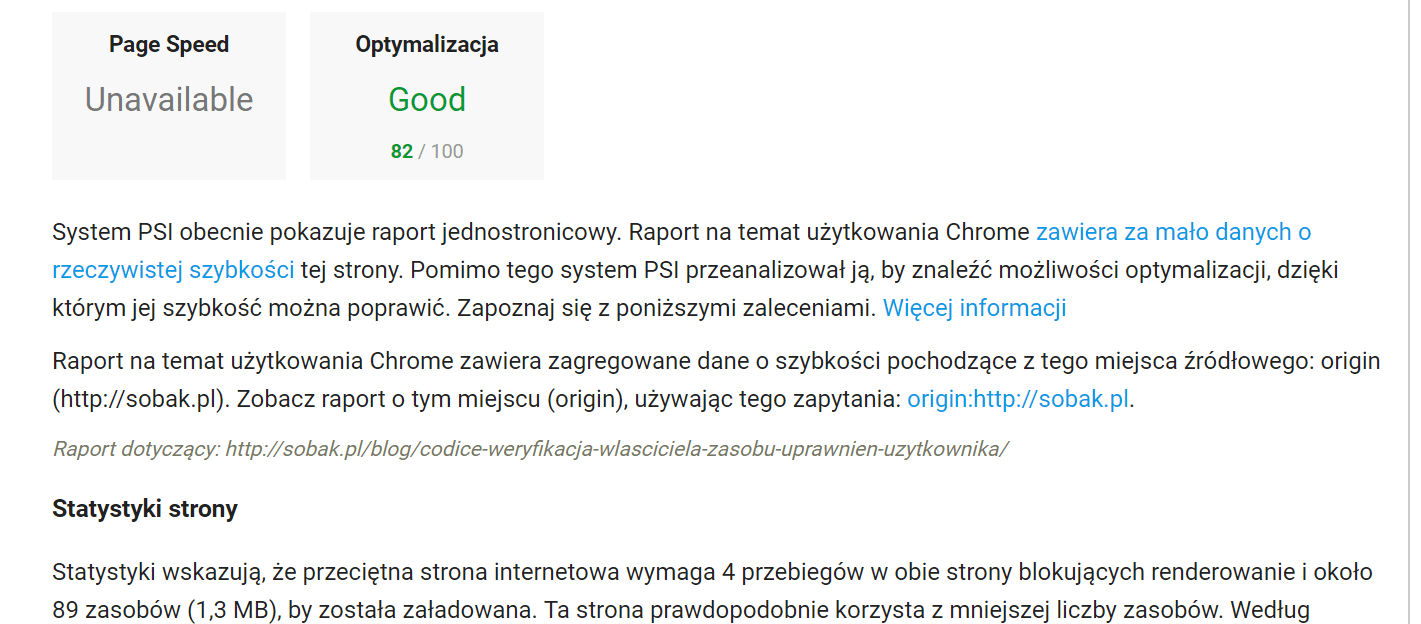
- PageSpeed Insights 2017
-
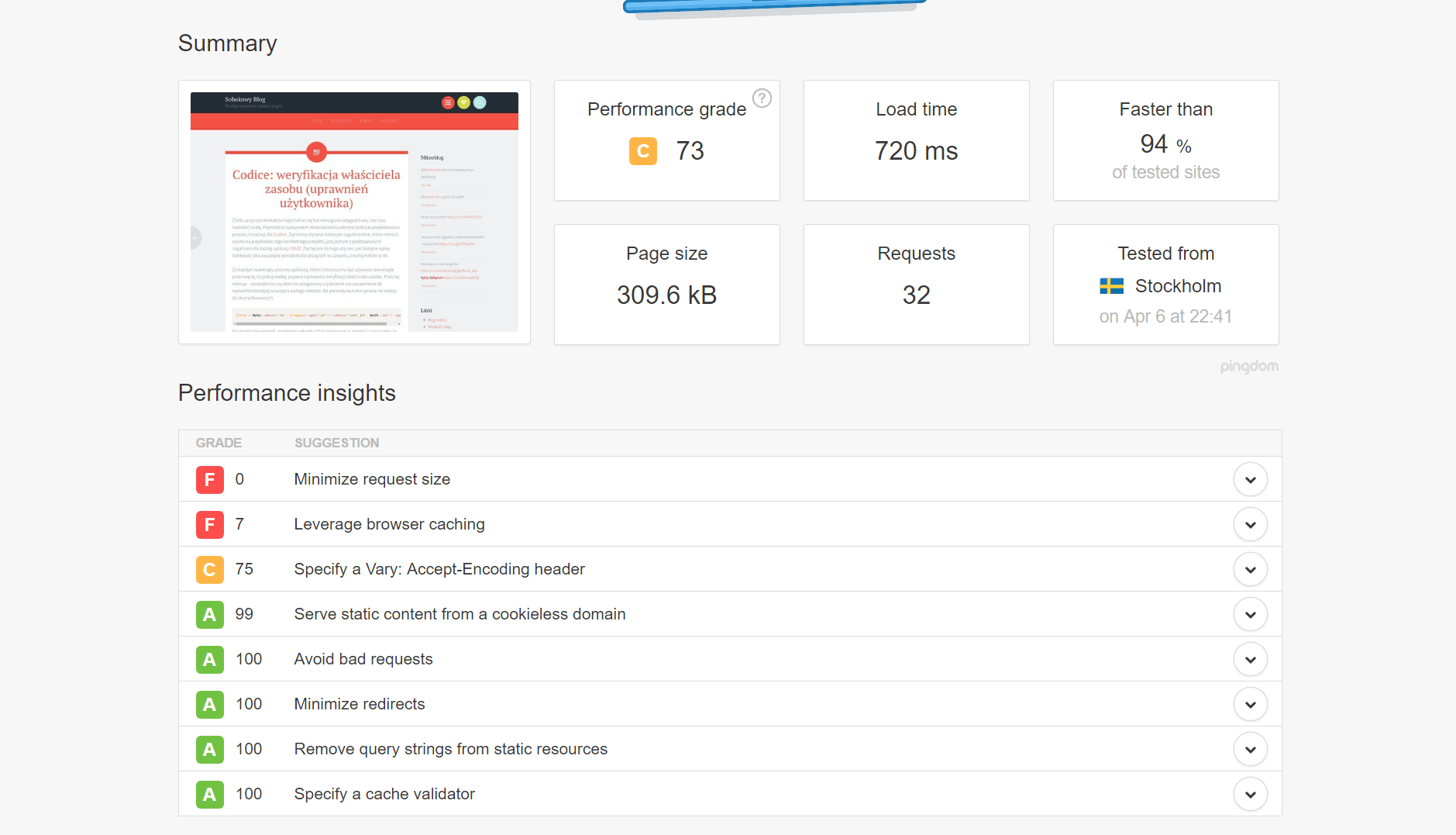
- Pingdom 2017
-
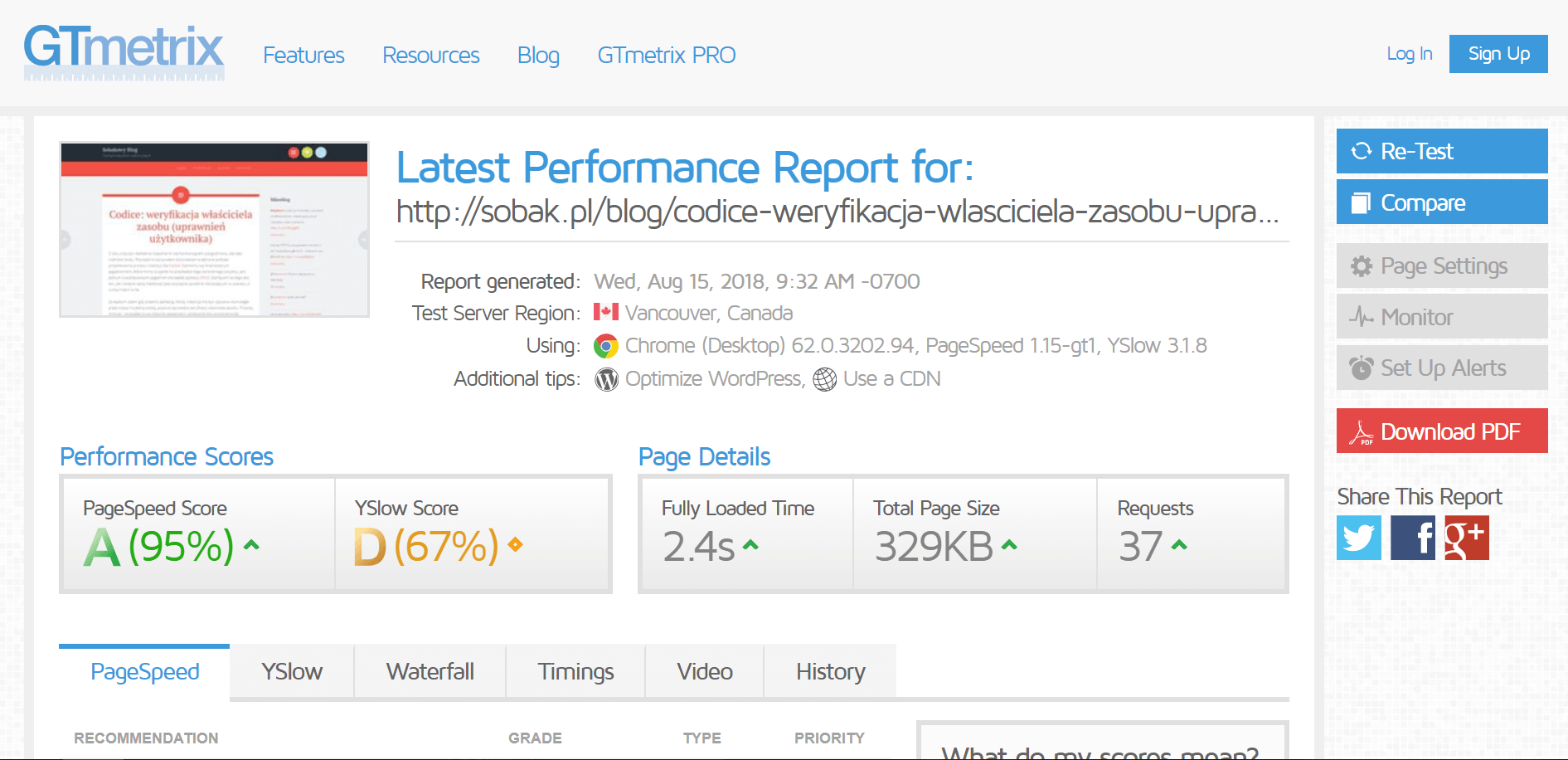
- GTmetrix 2017
-
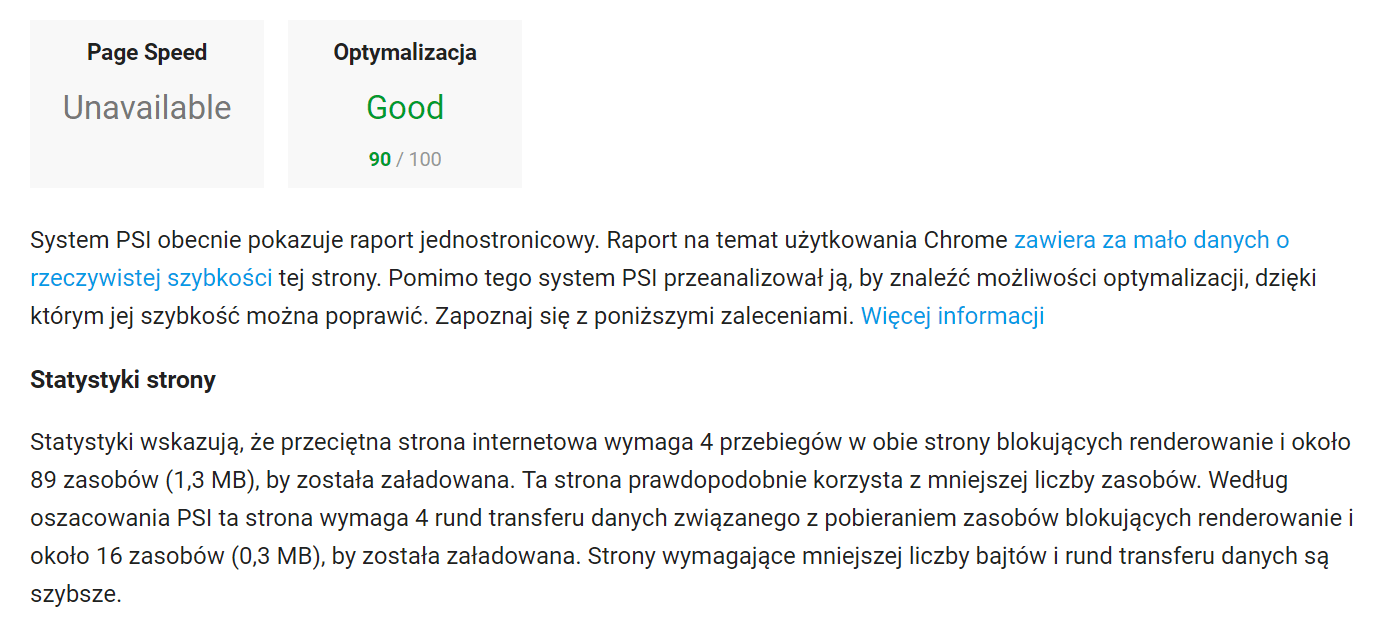
- PageSpeed Insights 2018
-
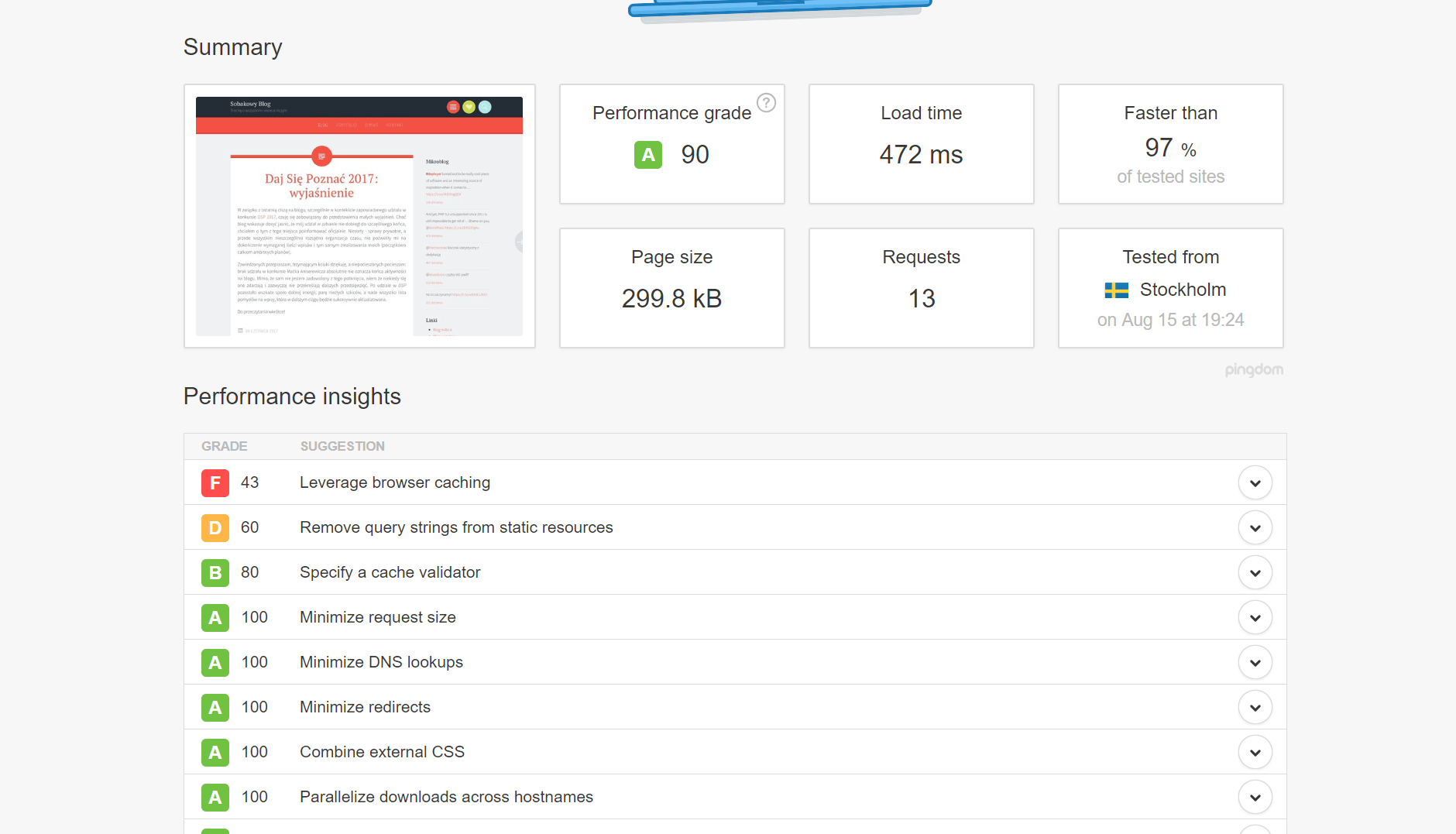
- Pingdom 2018
-
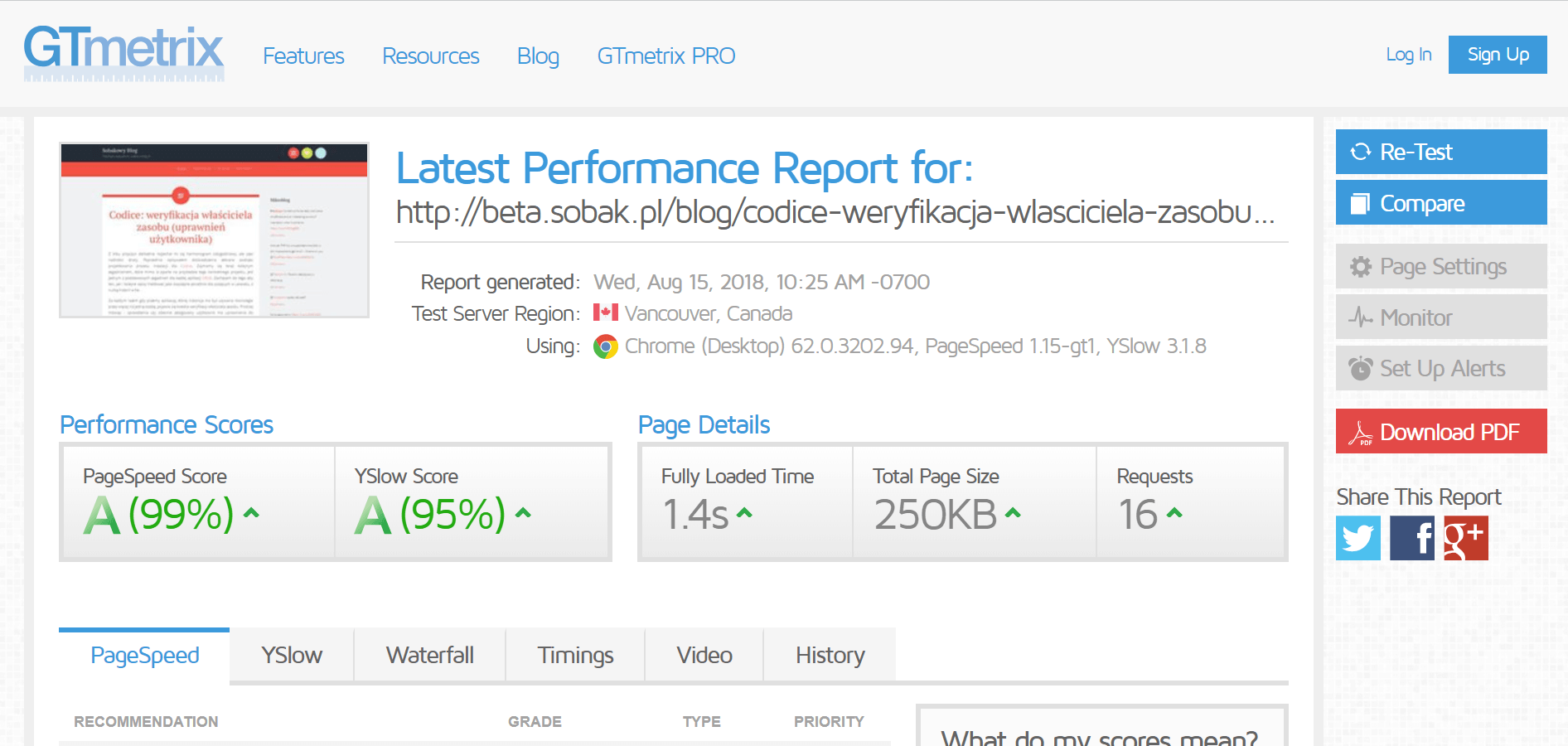
- GTmetrix 2018
Pimp my website
Mimo iż nie zdecydowałem się na całościową wymianę szablonu strony, znalazłem dziesiątki, jeśli nie setki pomniejszych rzeczy zasługujących na poprawę w obecnym. Poczynając od rzeczy ogólnych jak zwiększenie kontrastu tekstu, o które prosiliście niedługo po premierze poprzedniej wersji (4 lata, polecam się), przez poprawę typografii, marginesów, kolorów, spójności i podrasowanie pojedynczych podstron, jak portfolio. Więcej szczegółów we wmiaręwykazie zmian na dole wpisu.
Content is an old, impotent king
Wydaje mi się, że blog z założenia jest formą treści, która po czasie zaczyna stanowić pewną historię, więc nie ingerowałem za bardzo w samo sedno byłych wpisów. Nie da się jednak ukryć że przez ponad osiem lat wiele z nich zaczęło odstawać od reszty strony, nie tylko stylistycznie lecz nawet w tak jaskrawe sposoby jak użycie już dawno nieużywanej wtyczki do podświetlania kodu. Poprawiłem też mnóstwo znalezionych po drodze literówek, niedziałających już dawno linków, a czasem nawet skrajnie nieaktualnych lub błędnych informacji (to ostatnie jednak robiłem w drodze wyjątku).
W kontekście treści warto też wspomnieć o porzuceniu możliwości komentowania na mojej stronie. Nad trudnościami technicznymi przeważyły problemy z moderowaniem takiej ilości tekstu i późniejszym utrzymaniu go w ryzach. Wierzę że komentujący mi wybaczą i z formularza na dole wpisów zapraszam do kontaktu w dowolnym miejscu wykazanym w zielonym menu (ikona serduszka na prawo od nagłówka).
Projekty stare i nowe
Sporo aktualizacji otrzymało portfolio. Poza poprawkami stylów, drobnymi korektami wielu z miniaturek, skupiłem się także na aktualizacji zawartej tam treści. Rozbudowałem opisy wielu z projetków, te które doczekały się nowych wersji zyskały często osobne podstrony w portfolio, aby oddzielić je od historycznych już tworów. Wreszcie, opisałem także kilka nowych dzieł.
Pastebin, czyli nowe miejsce do dzielenia się fragmentami kodu źródłowego, które w obecnej formie powstało kilka nocy temu.
Blackout — opus magnum spierdolenia szczyt projektów bezsensownych,
nieuzasadnionych i z góry skazanych na porażkę, czyli moje starcie z opisywaną już bestią,
bossem projektów legacy — xNovą.
Codice, które od ostatniej aktualizacji pozycji w portfolio stało się zupełnie nowym, otwartoźródłowym projektem. Dawniejsza wersja i delikatny rys historyczny poprzednich podejść został przeniesiony na osobną podstronę.
I wreszcie zupełnie nowa odsłona sobak.pl w portfolio. Podobnie jak wyżej, dawna treść została zachowana w osobnym, podlinkowanym miejscu.
Co dalej?
W chwili gdy to piszę, z mojego osobistego todo znika najbardziej rozbudowany i pożądany punkt od niemal roku. Mogąc się teraz zabrać za inne rzeczy, bez jednoczesnego wywoływania wyrzutów sumienia, planuję okazać trochę miłości starym, zakurzonym projektom, jak i zająć się rozwojem kilku nowszych. Stay tuned!
…ach, nie spodziewajcie się jednak w najbliższym czasie nowych tworów wielkoformatowych pokroju Codice czy codziennych aktualizacji o postępie prac. Stety-niestety gimnazjum mam już za sobą, a programowanie zawodowe skutecznie ogranicza ilość sił i zwyczajną ochotę na dalsze zagłębianie się w kod w czasie wolnym. Postaram się jednak aby każdy miesiąc przyniósł jakąś nową informację o mnie i tym nad czym pracuję.
W-miarę-wykaz zmian
- znacząco poprawiłem czas ładowania strony (porównanie wyżej)
- wdrożyłem certyfikat SSL dla sobak.pl i wszystkich subdomen
- gorsza wiadomość: ze względu na ograniczony czas wycofałem możliwość komentowania wpisów
- oparłem podświetlanie bloków kodu źródłowego o Keylightera
- przerobiłem podgląd wpisów z Twittera, które teraz w większości wypadków ładują się natychmiastowo
- zamieniłem strzałki do paginacji miejscami (następna strona po prawej)
- zmodyfikowałem listę linków w sidebarze tak aby ich kolejność była losowa
- poprawiłem wyszukiwarkę tak aby poprawnie obsługiwała przycisk Czytaj dalej dla wpisów, które go posiadają
- poprawiłem wyszukiwarkę tak aby pokazywała także normalną paginację, a nie tylko strzałki po bokach ekranu
- dodałem link do profilu na LinkedIn do menu serwisów społecznościowych
- otwarcie menu wyszukiwania ustawia teraz kursor w polu formularza
- poprawiłem podświetlanie aktywnego elementu menu na wielu podstronach
- formularz kontaktowych korzysta teraz z ReCAPTCHA
- przywróciłem do życia overdocs.net
- zmiany wizualne:
- zwiększyłem kontrast tekstu
- poprawiłem style portfolio (w tym responsywność)
- poprawiłem style formularza kontaktowego
- poprawiłem wyświetlanie menu na urządzeniach mobilnych
- poprawiłem typografię tekstu
- poprawiłem style nagłówków
- poprawiłem style cytatów
- poprawiłem style dla wielu wariantów wyświetlania list
- poprawiłem wyświetlanie miniaturek w portfolio
- dodałem style dla boxów z informacją/ostrzeżeniem
- zmniejszyłem wagę fonta dla pogrubionego tekstu
- zmniejszyłem delikatnie marginesy dla akapitów
- dodałem zawijanie bloków kodu po 450px wysokości na urządzeniach mobilnych
- wiele mniejszych lub zapomnianych poprawek
- zmiany w treści (lista niepełna):
- poprawiłem kilkadziesiąt literówek i miejsc z błędnym formatowaniem tekstu
- poprawiłem wiele niedziałąjacych i przestarzałych linków
- zoptymalizowałem wagę niemal wszystkich obrazków wyświetlanych na stronie
- połączyłem podobne tagi dla wpisów
- portfolio
- dodałem opis projektu Pastebin
- dodałem opis projektu Blackout
- zaktualizowałem opis projektu Codice (opis starej wersji został wydzielony do osobnej podstrony)
- zaktualizowałem opis projektu dla sobak.pl (opis starych wersji, opartych o WordPressa został wydzielony do osobnej podstrony)
- zaktualizowałem opis projektu WordPress Cleaner
- wiele pomniejszych poprawek
- stats.sobak.pl
- dodałem podstawowe statystyki z GitHuba
- kliknięcie w nazwę serwisu kieruje teraz bezpośrednio do mojego profilu